Reasoning-Modelle sind teuer, sehr teuer
Gut für die Schaufelverkäufer, schlecht für die Goldgräber.

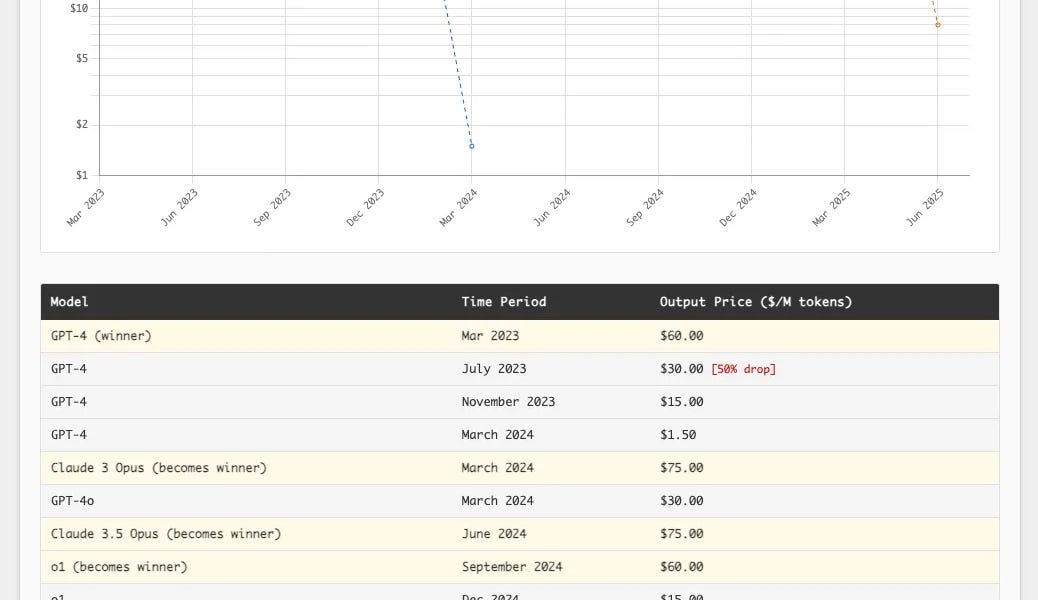
Seit dem GPT-5 Update nutzen viele ChatGPT-Nutzer vermehrt (manche sogar zum ersten Mal) ein Reasoning-Modell wie GPT-5 Thinking, weil es im „Auto“-Modus automatisch bei komplexen Fragen aktiviert wird. Die meisten Nutzer haben zuvor nie den Modell-Picker verwendet, um manuell o3 oder o4-mini auszuwählen (Stichwort: The power of defaults). Generell führt das in den meisten Fällen zu besseren Antworten, auch wenn man sich in Geduld üben muss. Für Nutzer ist das aus meiner Sicht also ein Erfolg. Wer sich ebenfalls darüber freut, ist Nvidia, die vom „Denkprozess“ (Chain of Thought) der Reasoning-Modelle profitieren, weil sie mehr Tokens und damit mehr GPU-Leistung benötigen. Wer also nach den teilweise enttäuschenden Earnings diese Woche dachte, dass Nvidia seinen Zenit überschritten hat, könnte schon bald eines Besseren belehrt werden.
Gleichzeitig ist das aber zumindest kurzfristig eine schlechte Nachricht für diejenigen, die auf der anderen Seite die GPUs kaufen und betreiben müssen, also OpenAI, Anthropic und Co. Ethan Ding beschreibt es so:
Imagine you start a company knowing that consumers won’t pay more than $20/month. Fine, you think, classic VC playbook – charge at cost, sacrifice margins for growth. you’ve done the math on CAC, LTV, all that. But here’s where it gets interesting: you’ve seen the a16z chart showing LLM costs dropping 10x every year.
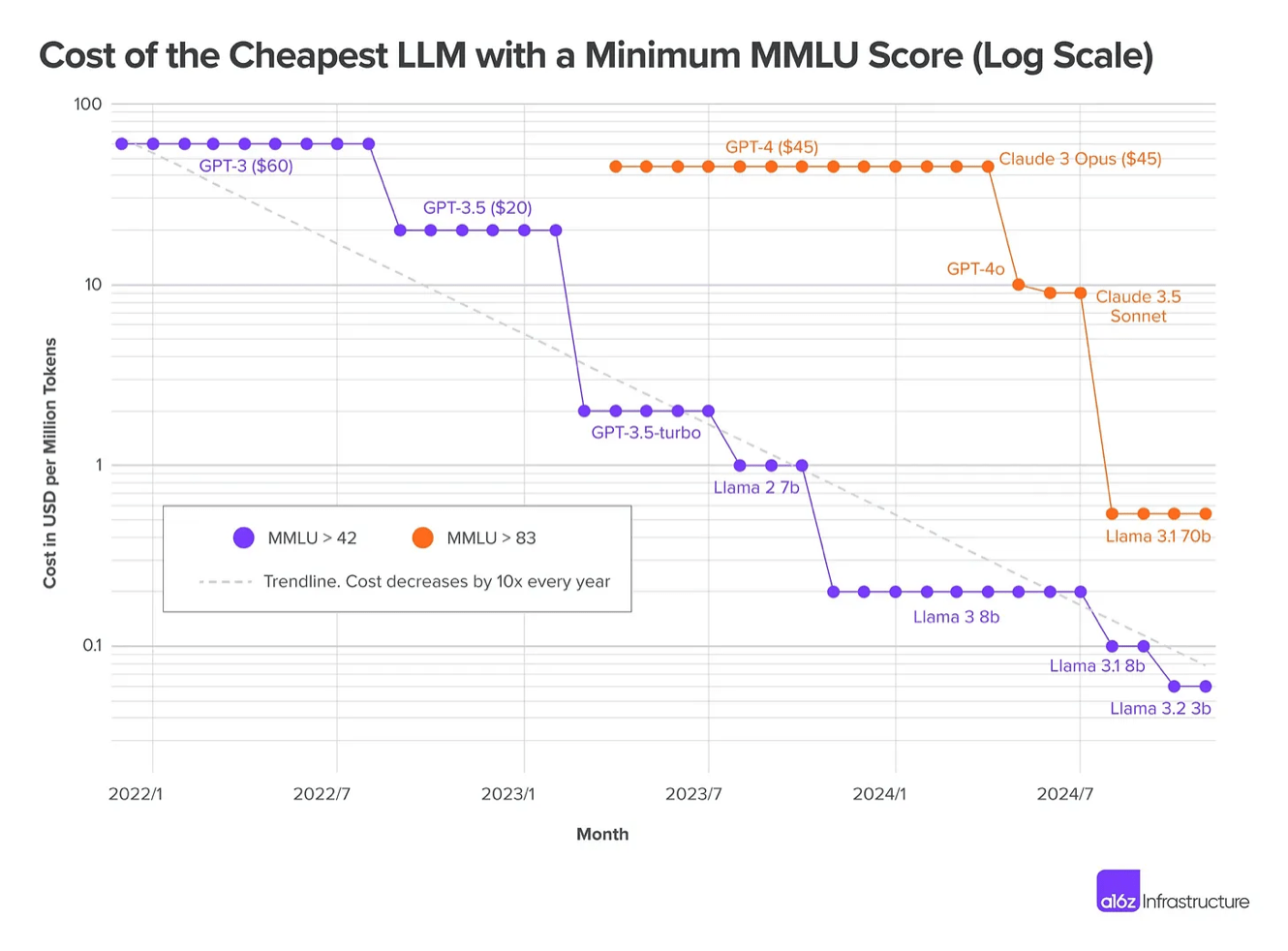
So you think: I’ll break even today at $20/month, and when models get 10x cheaper next year, boom – 90% margins. The losses are temporary. The profits are inevitable.
[...]
Demand exists for “the best language model,” period. And the best model always costs about the same, because that’s what the edge of inference costs today…When you’re spending time with an AI — whether coding, writing, or thinking — you always max out on quality. Nobody opens Claude and thinks, “You know what? Let me use the shitty version to save my boss some money.” We’re cognitively greedy creatures. We want the best brain we can get, especially if we’re balancing the other side with our time.
[...]
While it’s true each generation of frontier model didn’t get more expensive per token, something else happened. Something worse. The number of tokens they consumed went absolutely nuclear. ChatGPT used to reply to a one sentence question with a one sentence reply. Now deep research will spend 3 minutes planning, and 20 minutes reading, and another 5 minutes re-writing a report for you while o3 will just run for 20-minutes to answer “Hello There”. The explosion of RL and test-time compute has resulted in something nobody saw coming: the length of a task that AI can complete has been doubling every six months. What used to return 1,000 tokens is now returning 100,000.
Die AI-Startups befinden sich in einem Kopf-an-Kopf-Rennen um das beste Modell und haben daher keine andere Wahl, als diese exponentiellen Kosten einfach hinzunehmen und ihre ohnehin schon unprofitablen Unternehmen für einige Zeit noch unprofitabler zu machen. Außer sie monetarisieren endlich die 80–90 % kostenlosen Nutzer mit – ihr habt es erraten: Werbung.
